基本情形#
尽管RCT是估计处置效应的最清楚和最直观的方法, 但出于技术难度和道德伦理的限制, 很难运用到实践中. 除了RCT之外, 几种被称为 准实验设计(quasi-experimental design) 的方法被证明也能较好地估计因果效应, 双重差分(Difference-in-Differences, DiD) 就是其中的一种, 主要在政策评估领域中用来估计ATT.
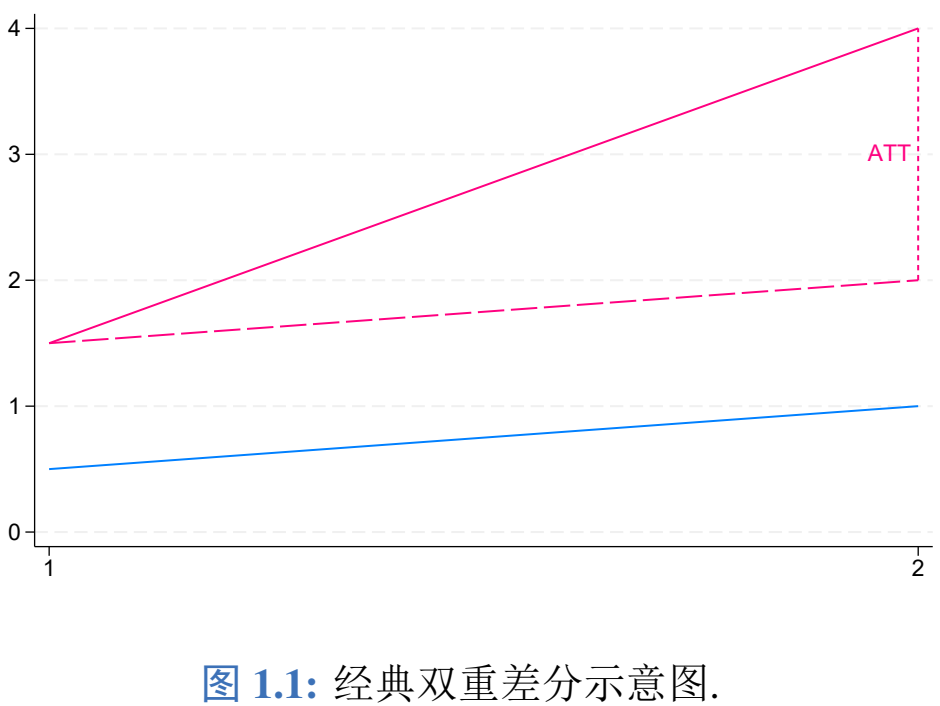
首先介绍经典的DiD, 研究者想知道某项在t=2时期实施的政策Di对结果变量Yi的影响, 也即ATT1
†τ=E[Yi,2(1)−Yi,2(0)∣Di=1]在SUTVA成立的情况下, ATT是良好定义的, 但我们无法识别出它. 在缺乏实施RCT的情境下, 需要做出一些额外假设才能正确识别ATT.
假设条件1
平行趋势: E[Yi,2(0)−Yi,1(0)∣Di=1]=E[Yi,2(0)−Yi,1(0)∣Di=0];
无预期效应: 对于所有Di=1的个体i都有Yi,1(0)=Yi,1(1).
平行趋势假设表明, 如果在t=2期没有政策冲击, 那么处置组和控制组的结果变量随时间变化的趋势应该一样的, 也即其他因素造成处置组和控制组的差异在t=1和t=2时期相同. 无预期效应表明, 受政策影响的个体在政策实施前的潜在结果相同, 也即政策在实施前不会对结果产生任何影响.
根据以上两个假设可以得到
E[Yi,2(0)∣Di=1]=E[Yi,1(0)∣Di=1]+E[Yi,2(0)−Yi,1(0)∣Di=0]=E[Yi,1(1)∣Di=1]+E[Yi,2(0)−Yi,1(0)∣Di=0]=E[Yi,1∣Di=1]+E[Yi,2−Yi,1∣Di=0]从而处置组处置效应可以被识别为
†τ=E[Yi,2−Yi,1∣Di=1]−E[Yi,2−Yi,1∣Di=0]上式第1项表示由于政策冲击和其他因素造成的处置组结果变量的平均差异, 第2项为其他因素造成的控制组结果变量的平均差异, 因此该方法称为2×2双重差分, 如图1所示.
类似地, 我们可以直接写出†τ的一致估计量
†τ^=(Yˉ2,1−Yˉ1,1)−(Yˉ2,0−Yˉ1,0)其中Yˉt,d是Di=d的所有个体i的结果变量Yi在t时刻的平均值. 除此之外, 还可以使用双向固定效应模型
Yi,t=αi+λt+(1[t=2]⋅Di)β+ei,t出自以上回归方程的OLS估计量β^数值上等价于†τ^, 这里的αi和λt分别为个体固定效应和时间固定效应, ei,t为随机扰动项. 此外, 如果{Yi,2,Yi,1,Di}i=1n是出自某个满足平行趋势假设的分布的i.i.d.随机样本, 那么在温和的正则条件下, 当n→∞时有
n(β^−†τ)dN(0,VDiD)交错时间处置#
在经典DiD的框架下, 政策在同一时刻发生, 且只包含了处置组和控制组, 然而政策可能具有滞后性, 因此经典DiD不再适用. 有鉴于此, 我们可以将2×2的经典DiD推广至多维, 也即存在多个组群在不同时点受到政策冲击.
假设时间跨度为T+1, 每个时点由t=0,⋯,T标记, 个体i可以在任意t≥0的时点受到二元处置, 并且处置是 吸收态(absorbing state), 也即一旦个体接受处置, 那么它在剩余的时间上保持被处置的状态. 我们使用Di,t作为个体i在时点t是否接受处置的二元指示符, Gi=min{t:Di,t=1}为个体i首次接受处置的时点, 同在Gi接受处置的个体i构成一个组群, Gi=∞表示个体i从未接受处置. 由于处置是吸收的, 因此对于一切t≥Gi都有Di,t=1.
我们需要推广潜在结果的表示方法. 设0s和1s分别为s维的0向量和1向量, 如果个体i在时点g首次接受处置, 那么它在t时刻的潜在结果为Yi,t(0g−1,1T−g+1), 而用Yi,t(0T)表示从未接受处置的潜在结果, 分别简写为Yi,t(g)以及Yi,t(∞), 并且
Yi,t(g)=Yi,t(∞)+0≤g≤T∑[Yi,t(g)−Yi,t(∞)]⋅1[Gi=g]同样地, 为了正确识别处置效应, 我们需要新的平行趋势和无参与效应的假设, 它们是前文所述假设的推广.
假设条件2
不可逆性: 对于一切个体i都有Yi,1=Yi,1(0), 并且Yi,t−1(1)意味着Yi,t(1).
平行趋势: 对于一切t=t′, g=g′都有E[Yi,t(∞)−Yi,t′(∞)∣Gi=g]=E[Yi,t(∞)−Yi,t′(∞)∣Gi=g′].
无预期效应: 对于一切i和t<g都有Yi,t(g)=Yi,t(∞).
这里的不可逆性意味着处置状态是吸收态, 个体一旦接受处置, 则在后续阶段一直属于处置组.
假设处置时点为g, 考虑使用如下静态TWFE模型
Yi,t=αi+λt+Di,tβpost+ei,t于是个体i在t时刻的ATT可以表示为
†τi,t(g)=Yi,t(g)−Yi,t(∞)如果对于所有的个体i, 当t≥g时总有†τi,t(g)=†τ, 并且不论处置时点过去了多久, 处置总有相同的效应, 那么在假设条件2下, 回归系数βpost=†τ.
但是当处置效应具有异质性时, OLS估计量β^post不再可行. 简单起见, 假设异质性以以下形式呈现
†τi,t(g)=s≥0∑†τs1[t−g=s]也即所有个体在接受处置后的第s个时期具有相同的处置效应†τs. 此时, βpost与τs的非凸加权平均联系在一起, 例如βpost=∑sωs†τs, 其中权重ωs之和为1但可能为负.
现在问题来了, 如果所有的τs均为正, 但是某个权重值ωs为负, 会不会导致回归系数βpost为负? 答案是肯定的. Goodman-Bacon (2021)证明了概率极限
n→∞plimβ^post=VWATT−VWCT+ΔATT其中VWATT是TWFE-DiD估计量所能解释的处置组平均处置效应, VWCT是方差加权的共同趋势, 并且它在平行趋势假设成立的情况下为0, ΔATT等于各组群在处置前后的处置结果变化的加权和, 也是负权重的来源.2 正如上面提到的, 如果处置效应是同质的 (也即ATT跨组群和时点保持不变), 那么ΔATT=0, 此时βpost正确识别了因果关系, 使用OLS估计静态TWFE模型是合理的.
为何会出现负权重? 根据FWL定理可知βpost的OLS估计量为
β^post=∑i,t(Di,t−D^i,t)2∑i,t(Di,t−D^i,t)Yi,t其中D^i,t是出自回归Di,t=αi+λt+ui,t的Di,t的拟合值. 由于上式分母始终为正, 以及Yi,t=Yi,t(∞)+τi,t(g), 因此如果Di,t=1且Di,t−D^i,t<0, 那么τi,t(g)在β^post中取得负权重, 即使个体i在t时刻接受处置.
进一步, 经过某些代数运算可得
D^i,t=Dˉi+Dˉt−Dˉ其中Dˉi=T−1∑tDi,t表示个体i的处置D在时间上的平均, Dˉt=N−1∑iDi,t表示时点t的处置D在截面上的平均, Dˉ=(NT)−1∑i,tDi,t表示处置D在整个截面和时间上的平均.
如果个体在几乎所有时点都是处置状态, 那么Dˉi≈1, 如果某时点几乎所有个体都被处置, 那么Dˉt≈1, 在二者同时成立的情况下有D^i,t≈2−Dˉ, 如果在某段时间内有部分未接受处置的个体存在, 那么D^i,t>1. 由此可见, 早期接受处置的个体在后期更容易产生负权重, 使用较早接受处置的组群作为控制组也被称为 禁止比较(forbidden comparison).
既然非同质处置效应会导致静态TWFE模型失效, 我们自然转向使用动态TWFE模型, 通常称为 事件研究设计(event study design), 具体如下
Yi,t=αi+λt+l=−K∑−2μlDi,tl+l=0∑LμlDi,tl+ei,t(C.14)其中, Di,t=1[t−Gi=l]是相对时间变量, Gi是个体i接受处置的时点, l是相对处置时点. 在上式中, 相对时间变量Di,t被分为了两组, 一组代表处置前 (l≤−2), 一组代表处置后 (l≥0), 各个μg体现了动态效应 (dynamic effects). 此外, 为了避免完全多重共线性, 选取l=−1作为基期. 这里的K=Gmax−1, L=T−Gmin, 并且Gmax和Gmin分别表示最晚和最早接受处置的时间.
然而, 单纯的事件研究仅能解决同质性处置效应路径的TWFE估计偏误,3 实践中经常用到的是稳健估计量.
Callaway-Sant’Anna估计量#
对于随时间和组群变化的一般性异质性处置效应路径, 可以使用Callaway and Sant'Anna (2021)提出的稳健估计量来解决TWFE估计偏误.
具体可以考虑
θ(g,t)=E[Yt(g)−Yt(∞)∣Gg=1]这里为了简单起见省略了下标i, Gg是个体i在时点g是否接受处置时的指示符, 上式表示在时点g首次接受处置的那批个体在时点t的ATT. 由于因果推断的根本难题, θ(g,t)是无法直接估计的, 但是可以由 回归调整(Regression Adjustment, RA), 逆概率加权和双重稳健方法来估计.
为了通过上述方法得到识别ATT, 需要先定义控制组, 而它的选择有两种: 其一是从未处置CNEV=G∞, 其二是尚未处置CNY=(1−Gg)(1−Dt), 以下统一记作Cg,t∗.
考虑加入用以控制可观测特征的协变量X, 下面给出RA, IPW和DR的待估计量
θRA(g,t)θIPW(g,t)θDR(g,t)=E[E[Gg]Gg{Yt−Yg−1−mg,t(X)}]=EE[Gg]Gg−E[1−pg,t(X)pg,t(X)Cg,t∗]1−pg,t(X)pg,t(X)Cg,t∗(Yt−Yg−1)=EE[Gg]Gg−E[1−pg,t(X)pg,t(X)Cg,t∗]1−pg,t(X)pg,t(X)Cg,t∗{Yt−Yg−1−mg,t(X)}其中mg,t(X)=E[Yt−Yg−1∣X,Cg,t∗=1], pg,t(X)=P[Gg=1∣X,Gg+Cg,t∗=1]. 在温和的正则条件下, Callaway and Sant'Anna (2021)证明了
θ(g,t)=θRA(g,t)=θIPW(g,t)=θDR(g,t)由于RA, IPW和DR只依赖于(Y,X,Gg,Cg,t∗), 因此可以通过它们得到θ(g,t)的估计量.
然而, 在长时间跨度和多处理时点的情况下, 报告每一个θ(g,t)是很麻烦的事情, 并且可能不准确, Callaway and Sant'Anna (2021)提供了将不同θ(g,t)进行加总的机制
θ=g∑t=2∑Tw(g,t)⋅θ(g,t)其中w(g,t)是某个精心挑选的权重函数, 用以解决特定的实证问题. 特别地, 设l=t−g为表示在接受处置后逝去的时间, 则关于l的一种加总方式为
θes(l)=g∑1[g+l≤T]⋅P[G=g∣G+l≤T]⋅θ(g,t)称为 事件研究参数 (event-study parameter), 它给出了在不同处置组群中, 在接受处置后e个时期的处置效应的加权平均值.
现在来看对θ(g,t)的估计, 根据Callaway and Sant'Anna (2021)的研究, 采取以下步骤是可行的
设t0=(g−1)1[t≥g]+(t−1)1[t<g], 将样本限制在时点t和t0上, 也即用于估计θ(g,t)的个体i必须在时点t和t0上可观测;
使用参数模型估计pg,t(X)和mg,t(X), 具体而言:
- 当Cg,t∗=1时用Yt−Yt0对X进行线性回归, 得到预测值m^g,t(X);
- 用Gg对X进行Logit回归, 得到预测值p^g,t(X);
将估计得到的m^g,t(X), p^g,t(X)插入RA, IPW或DR的表达式中, 并用样本均值替代期望算子.
最后, 对于θ^(g,t)的协方差矩阵的估计可以通过c影响函数法(influence function approach) 计算, 它在数值上等价于GMM得到的结果, 但运算速度更快. CS的估计和统计推断可以通过csdid2包在Stata和R中实现.
值得注意的是, 如果协变量Xg可以决定组群接受处置的时点, 那么这种处置时点的内生性可能导致平行趋势假设不成立, 此时使用CS估计量仍然是有偏的.
敏感性分析#
我们已经清楚, 无论是经典的DiD还是交错处置的DiD都依赖于必要的平行趋势假设, 然而这个假设本质上是无法检验的, 因此DiD的结果需要谨慎看待.
首先将整个时间窗口设置为[−K,L], 仍然考虑基本的TWFE模型
Yi,t=αi+λt+s=0∑1[s=t]×Di×βs+εi,t这里为了避免完全多重共线性剔除了s=0基期. 如果个体i在t=1时接受处置就将Di设置为1, 否则为0, 则经典DiD估计量
β^s=(Yˉs,1−Yˉs,0)−(Yˉ0,1−Yˉ0,0)数值上等于TWFE估计量, 其中Yˉs,d是Di=d的那些个体在时点s的结果变量的样本均值.
现在使用全体β^s构成列向量β^=(β^pre′,β^post′)′∈RK+L, 其中β^pre=(β^−K,⋯,β^−1), 以及β^post=(β^1,⋯,β^L), 它们分别收集了处置前和处置后的估计量. 在温和的条件下, 当样本容量N→∞时有N(β^−β)dN(0,Σ).
现在我们假设β可以被分解为
β==:τ(τpreτpost)+=:δ(δpreδpost),τpre=0其中τ表示感兴趣的处置效应, δ表示如果没有政策冲击(处置), 控制组和处置组的趋势差异. 当无预期效应成立时有τpre=0, 而当平行趋势成立时有δpost=0, 因此βpost=τpost. 可以证明, 在经典DiD和事件研究的框架下, β都可以被这样分解. 例如
βs=†τs+=:δsE[Yi,s(0)−Yi,0(0)∣Di=1]−E[Yi,s(0)−Yi,0(0)∣Di=0]其中†τs=E[Yi,s(1)−Yi,s(0)∣Di=1], 在无预期效应条件下, 对任意s<0都有†τs=0, 这就完成了分解.
由于事前趋势检验难以真正检验平行趋势是否成立, 实行敏感性分析或许是一个更好的选择. 现在我们关注的目标参数是处置后因果效应的线性组合θ=l′τpost, 其中l是已知的L×1维向量. 通过将δ置于可能的趋势差异集Δ⊂RK+L中, 参数θ可以被 部分识别(partial identified). 例如, 将δ限制在Δ={δ:δpost=0}中就意味着平行趋势假设成立.
在违反平行趋势假设δ∈Δ={δ:δpost=0}的情况下, 参数θ被部分识别, 识别集是在δ∈Δ的限制条件下, 与β的给定值相一致的θ值构成的集合
S(β,Δ)={θ:∃δ∈Δ,τpost∈RLs.t.l′τpost=θ,β=δ+(0τpost)}可以证明, 如果Δ是闭和凸的, 那么识别集S(β,Δ)是R上的区间[θlb(β,Δ),θub(β,Δ)], 其中
θlb(β,Δ)θub(β,Δ)=l′βpost−(δmaxl′δposts.t.δ∈Δ,δpre=βpre)=l′βpost−(δminl′δposts.t.δ∈Δ,δpre=βpre)Rambachan and Roth (2023)给出了如何通过选取合适的Δ, 得到合适的DiD估计区间:
研究者可能愿意假设造成处置后非平行趋势的混杂因素在量级上不会比处理前的混杂因素大太多, 这可以正式地表述为δ∈ΔRM(Mˉ), Mˉ≥0, 其中
ΔRM(Mˉ)={δ:∀t≥0,∣δt+1−δt∣≤Mˉ⋅s<0max∣δs+1−δs∣}这里的ΔRM(Mˉ)用Mˉ乘以处置前最大平行趋势违反来约束处置后连续时期之间的最大平行趋势违反. 比方说, 如果造成平行趋势不成立的混杂经济冲击在前后期相似, 那么选取ΔRM(Mˉ)可能是合理的.
研究者可能担心长期趋势带来的对平行趋势的干扰 (例如劳动力供给的长期变化), 但这种趋势随着时间推动而平稳演变, 此时的趋势差异集为
ΔSD(M)={δ:∣(δt+1−δt)−(δt−δt−1)∣≤M,∀t}其中参数M≥0控制了δ的斜率在连续周期之间可以变化的幅度, 由此限制了离散二阶导数的范围. 当M=0时, ΔSD(0)要求趋势差异是线性的, 这与实际应用中常见的参数线性假设相对应.
考虑多面限制(polyhedral restriction) 的情况以便研究者依赖于特定知识来施加限制, 此时Δ={δ:Aδ≤d}, 这里的A和d分别是已知的矩阵和向量.
根据Monte Carlo模拟的结果, 对于一般和多面形式的Δ, 推荐使用ARP的条件混合方法, 而对于ΔSD(M)和其它满足一致性和有限样本近最优性条件的特殊情况, 则推荐使用FLCI. 这些方法的使用具体见作者提供的HonestDiD命令包, 并且还提供了例子.
参考文献#
Callaway B, Sant’Anna P H. Difference-in-Differences with multiple time periods[J]. Journal of Econometrics, 2021, 225(2): 200-230.
Goodman-Bacon A. Difference-in-Differences with variation in treatment timing[J]. Journal of Econometrics, 2021, 225(2): 254-277.
Rambachan A, Roth J. A More Credible Approach to Parallel Trends[J]. Review of Economic Studies, 2023, 90(5): 2555-2591.

{kind=link}